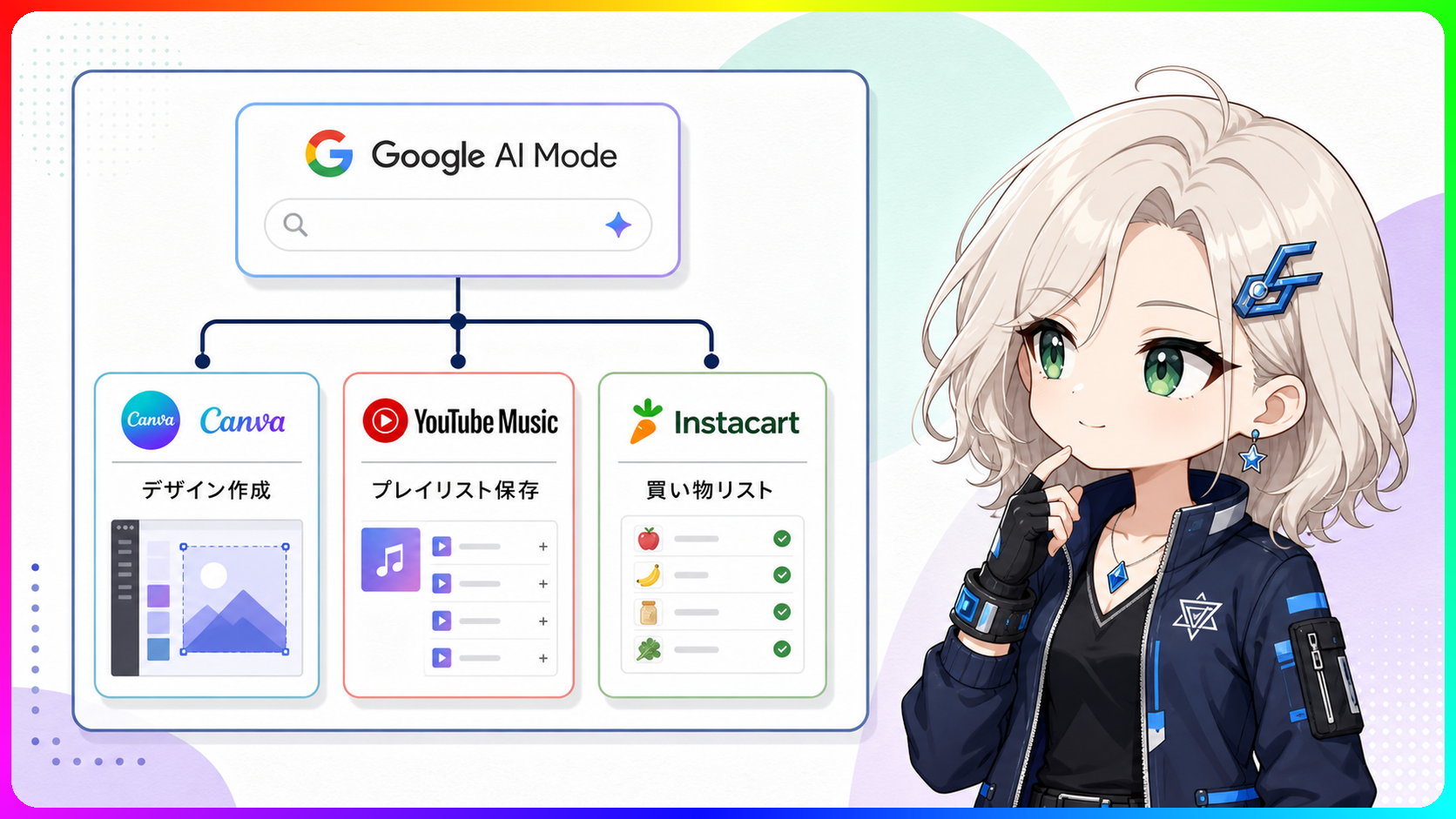
Google検索のAIモードがCanvaやYouTube Musicと連携。検索画面で何ができるようになる?
旅行の準備でGoogle検索を開いたとき、気に入ったテンプレートをCanvaに貼り付けて案内を作り、また別タブでYouTube Musicのプレイリストを探す。そういう画面の行き来、ありますよね。それが検索画面のまま完結する方向に進んでいます。 AIモードで調べた結果が、そのまま外部アプリへ渡される 2026年7月16日、Googleは検索のAIモードで外部アプリと直接連携する機能の提供を発表しました。 最初の連携先はCanva、YouTube Music、Instacartの3サービスです。AIモードの画面内で連携先のアカウントをリンクして、検索の流れのまま次の作業へ進めます。 米国では2026年7月20日前後から段階展開が始まる予定と報じられています。日本での提供開始時期は、2026年7月18日時点で公式案内が出ていません。現状では、日本から試せる機能ではありません。 3サービスで、何ができるか Canvaとの連携 AIモードに「誕生日パーティの案内を作りたい」と入力してテンプレートを提示してもらい、そのままCanvaのデザイン編集画面へ進めます。 「Googleで検索して、Canvaを別で開いて、またデザインを探して」という流れが、検索からデザイン作成まで一本でつながります。 YouTube Musicとの連携 「90年代のジャズを集めたプレイリストを作って」と依頼し、AIモードが出した候補をそのままYouTube Musicに保存できます。 気に入ったリストをメモして、YouTube Musicで手作業で再構成する手間がなくなります。 Instacartとの連携 「鶏むね肉と夏野菜を使った献立を提案して」という流れで作った買い物リストを、Instacartのカートに直接追加できます。カートに入れた後の注文手続きはInstacartのアプリまたはWebサイトで行います。 Instacartは日本での知名度はまだ高くないですが、米国では大手の食料品配達サービスです。今後の連携先に日本でなじみのあるサービスが加わると、この機能が一気に身近になります。 GeminiアプリのSpark機能との並走 Googleはこれと前後して、GeminiアプリのGemini Sparkでも同様の連携拡大が進む形です。 2026年6月30日には、Gemini SparkでCanvaやInstacart、Dropbox、OpenTable、Zillow Rentalsとの連携拡大を案内しています。Web・モバイルは翌週から、macOSアプリは数週間以内の展開予定とされています。 検索のAIモードとGeminiアプリ、両方から外部サービスへつながる設計を同時に進めている形です。利用する場面によって入口を選べるようになります。 外部アカウント連携とデータ共有の範囲 ちょっと気になるのは、外部アカウントをリンクする際にどのデータが共有されるか、という部分です。Googleは「安全にリンクする仕組み」とアナウンスしています。具体的な共有範囲は、設定画面と公式の詳細案内で確認するのが確実です。 連携先が増えると、その分データの流れが複雑になります。使い始める前に、各サービスの連携解除の手順は確認しておきたい。どのデータが渡るのかを把握した上で使うのと、なんとなく許可するのとでは、安心感がだいぶ変わります。 日本での展開を待つあいだに 今回発表された機能が日本でいつ使えるかは、現時点で不明です。 Googleは検索とGeminiアプリの両方で、外部サービスと直接つながる方向を明確に進めています。日本での展開が始まる前でも、米国での使われ方と今後の連携先の顔ぶれを追っていくと、この機能がどんな場面で役立つかが見えてきます。 日本展開の情報が出たら、また掘り下げるつもりです。 参考 ITmedia NEWS - Google検索の「AIモード」、検索結果からそのままアプリで作業可能に(https://www.itmedia.co.jp/news/articles/2607/17/news061.html) Google Blog - Gemini Spark updates June 2026(https://blog.google/innovation-and-ai/products/gemini-app/gemini-spark-updates-june-2026/)