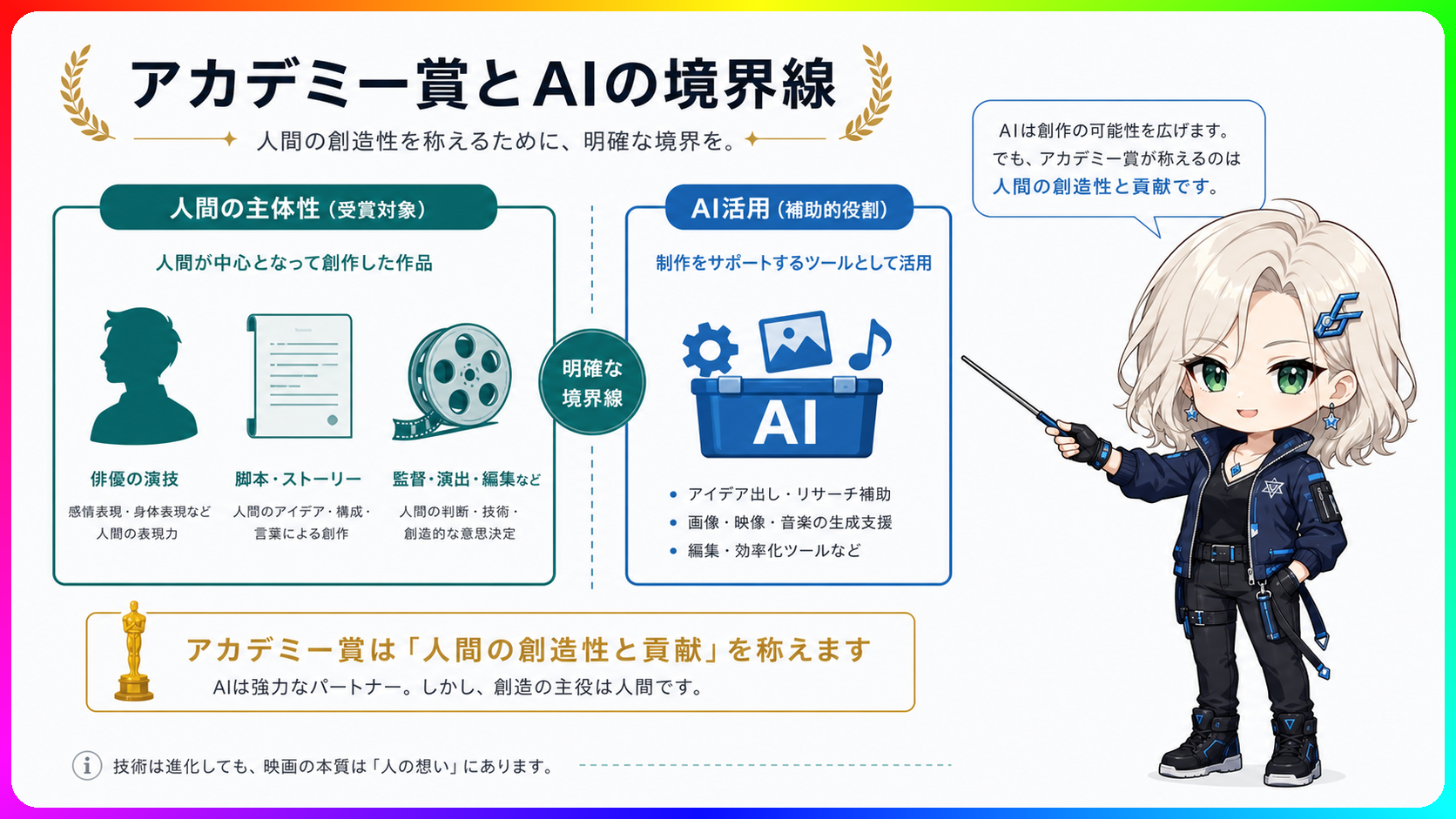
アカデミー賞がAI俳優・AI脚本を対象外に。人間の創作の中心はどこか
仕事でAIに文章を手伝わせる。画像案を出させる。資料の骨子を整えさせる。そういう使い方が当たり前になってきた2026年、ハリウッドの映画賞がひとつの線を引きました。 2026年5月1日、米映画芸術科学アカデミーが第99回アカデミー賞の新ルールを承認しました。俳優賞と脚本賞の対象を「人間が同意して演じた」「人間が書いた」に限定する内容です。AIを使うこと自体の禁止ではありません。人間が創作の中心にいたかどうかを、賞の基準として明文化した形です。 映画業界の規則に見えますが、AIを仕事で使う人なら誰にでも関係する問いがここには含まれています。 俳優賞・脚本賞に加わった新条件 米映画芸術科学アカデミーの理事会は2026年5月1日、第99回アカデミー賞の賞規則を承認しました。対象となる長編映画の劇場公開期間は2026年1月1日から12月31日で、主要な提出締切は2026年8月13日以降に始まります。今年後半に公開される作品から、このルールが初めて実際に問われます。 変更のポイントは二つです。 俳優部門では、映画のクレジットに記載され、人間が同意したうえで実際に演じた役柄だけがノミネートの対象になります。故人の俳優をAIで再現した映像や、AIで一から合成したキャラクターを「人間の演技」として評価することはしない、という整理です。 脚本部門では、脚本クレジットが必要で、その脚本は人間が書いたものでなければなりません。AIが初稿を生成して人間が全面改稿した場合をどう扱うかは、現時点のルール文書には明示がありません。 アカデミーの公式ルール文書には、生成AIやその他のデジタルツールを使うこと自体はノミネートの可能性に有利にも不利にも働かない、と明記されています。判断の基準は「人間が創作の中心にいたか」です。AP通信の報道によると、アカデミー会長は「人間が創作プロセスの中心にいる必要がある」と述べています。疑義がある場合、アカデミーは映画制作者に対し、AI利用の内容と人間の著作性について追加情報を求める権利も持ちます。灰色地帯の案件は、審査の場で個別に判断されるということです。 なぜ今この明文化が必要になったのか 2023年、ハリウッドでは俳優と脚本家が大規模なストライキを行いました。AIによる脚本生成、俳優の肖像や声の無断使用、制作現場の雇用への影響が主な争点でした。その後も変化は続いています。 AIで一から合成した俳優キャラクターが映画に登場し始め、故人の俳優をAIで再現する企画も出てきました。テキストから動画を生成するモデルの精度も上がり、「これは本物の俳優の演技なのか」という判断が難しい場面が増えています。映像を見て、あれ本物?と思った経験がある人もいるのではないでしょうか。 アカデミーが今回まとめたのは、こうした状況への回答です。AIは映画制作のツールとして使える。ただし、俳優賞と脚本賞は人間の表現を評価するものである、という線引きです。「AIを使った映画を全面的に排除する」のではなく、評価の対象を「人間の創作」に明確に絞った、という整理に近いです。 「AIを使った」と「AIが中心だった」の違い 今回のルールで問われているのは、AIをどう使うかではなく、人間がどこにいるか、です。 脚本の構成案をAIに出させて、そこから人間がゼロから書き直した場合はどうか。AIが生成した初稿を人間が大幅に加筆した場合は。現時点のルールは、こうした細則まで明示していません。アカデミーが「疑義がある場合は追加情報を求める」としているのは、判断がケースバイケースになることを前提にしているからです。 読んでいて引っかかったのは、この「人間が創作の中心にいたか」という問いの広がりです。映画賞のルールですが、資料作成、コンテンツ制作、デザイン、広告コピーなど、成果物に責任が伴う仕事全般で同じ問いが立ち始めています。「AIを使ったか否か」だけでは、もはや問いとして不十分になってきているのです。 AIを仕事で使うとき、責任はどこにあるか AIに下書きを任せた文章、AIが生成した画像をベースにしたデザイン、AIが提案した構成をそのまま使ったプレゼン資料。どれもAIを使ったという点は同じでも、どこに人間の判断が入っているかは大きく異なります。 会社でAI導入が進むと、「誰の同意で、誰の判断で、どこに人間の表現が残っているか」という問いは避けられなくなってきます。アカデミーはその問いを、賞の基準という形で明文化しました。映画業界の出来事ではありますが、仕事でAIを道具として使うすべての人に関係する論点が、このルールには詰まっています。 第99回アカデミー賞の審査が動き出す2026年8月以降、このルールが実際にどう運用されるかは、映画業界だけでなくAIを使う仕事人全体への問いにもなります。わたしとしては今のうちに、自分の仕事のどこに判断と責任があるかを整理しておきたいと思っています。 参考 TechCrunch - AI-generated actors and scripts are now ineligible for Oscars(https://techcrunch.com/2026/05/02/ai-generated-actors-and-scripts-are-now-ineligible-for-oscars/) Academy Press Office - AWARDS RULES AND CAMPAIGN PROMOTIONAL REGULATIONS APPROVED FOR 99TH OSCARS(https://press.oscars.org/news/awards-rules-and-campaign-promotional-regulations-approved-99th-oscarsr) AP News - Oscars organization expands international film eligibility, addresses AI in new rules(https://apnews.com/article/oscars-new-rules-artificial-intelligence-international-film-95a66f19bd0a95d371ac82f21df1a0f4) 米映画芸術科学アカデミー 第99回アカデミー賞完全ルール(https://www.oscars.org/sites/oscars/files/2026-05/99th_oscars_complete_rules.pdf?VersionId=84FilOcTNI7wpFAxl56.8xesZyP5.UWl)